We have nothing but a video file encoded in a base64 inside the
HTML page.
If we play it will show a bunch of text images.
On the first frame we see Java class that has name RunMe.
We need to run the whole class to recieve the anwser.
We cannot use brutforce
to crack the url, because the number is too high.
In the metadata of the file we can find the framerate. It is 20
frames per second.
Let's split the video into list of images with:
ffmpeg -i video.mp4 out%d.jpg -hide_banner
We will recieve all frames as images with resolution of 2800x1170 pixels.
For example the 31st frame looks like:
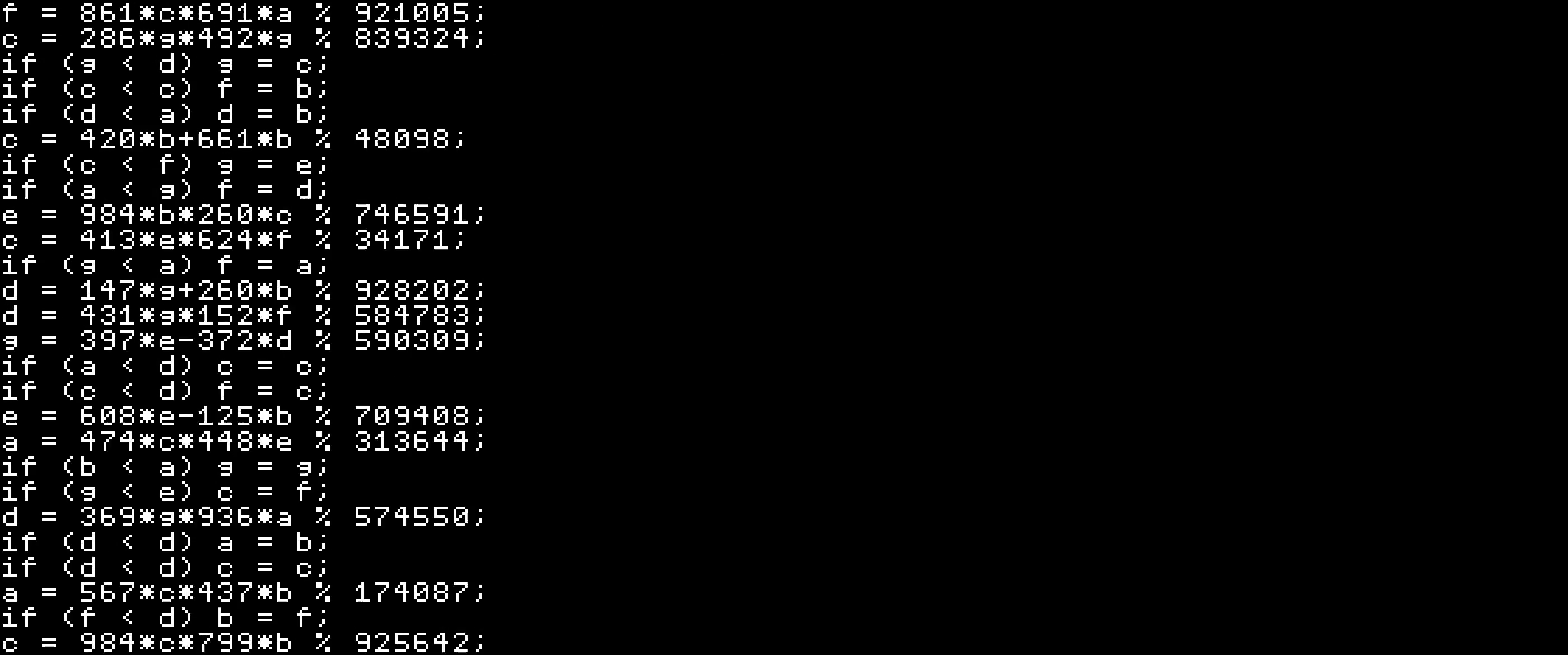
Here you can download all frames.
But the most part of the frame is black. Also we need to think out the solution
to recognize and convert monospace characters to text. So let's resize the image
and put each letter to the box 36x25 pixels like below:

Each letter consist of "big" pixels 5x5. So we need to downgrade
the quality in 5 times. So each pixel in the letter will be equal to one
physical pixel.
So lets write a script that takes an image and outputs it's text.
For example letter e will be converted to:
[ [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 0, 0], [0, 1, 0, 0, 0, 1, 0], [0, 1, 1, 1, 1, 1, 0], [0, 1, 0, 0, 0, 0, 0], [0, 0, 1, 1, 1, 1, 0], [0, 0, 0, 0, 0, 0, 0] ]
Here you can download full code.
Usage: ocr.py <start> <end>.
After we run the script on each frame we will have file with some errors. We need to fix unknown letters. And after that we have clean file, that we can run. And this is our putput in the console:
url: /5987001076
If we go to this url we will see
congratulations page
whith the link to the Level 12
(
task /
solution
)